
Et dynamisk workflow i Claude Code er et JavaScript-script, der styrer en stor flok subagenter på én gang. Du beskriver opgaven, Claude skriver scriptet, og så kører det i baggrunden, mens du roligt kan arbejde videre. Det smarte er, at Claude ikke længere selv skal regne ud tur for tur, hvad der så skal ske. Hele planen ligger nu i kode, både løkken, forgreningerne og mellemresultaterne, og den kan du læse, godkende og køre igen.
Kort sagt sætter et workflow dusinvis af agenter i gang på den samme opgave samtidig. Det gør dem stærke til de tunge opgaver: kodebase-audits, migreringer på tværs af hundredvis af filer eller research, hvor mange kilder skal krydstjekkes. Men de er også markant dyrere end en almindelig samtale. Funktionen er helt ny, så det her er en tidlig gennemgang af, hvordan den virker, og hvad vi indtil videre har set: både hvorfor workflows er så stærke, og hvorfor de koster, som de gør.
Et workflow flytter planen fra Claudes hoved og ind i et script. Det er hele forskellen, og det forklarer både styrken og prisen.
Subagenter, skills og workflows: hvem holder planen?
Subagenter, skills og workflows kan alle klare en opgave med flere trin. Det, der adskiller dem, er egentlig bare to ting: hvem holder planen, og hvor ender alle mellemresultaterne?
- Subagenter er arbejdere, Claude sætter i gang. Claude bestemmer tur for tur, hvad der skal køre, og hvert resultat lander tilbage i Claudes kontekstvindue. Fint til et par delegerede opgaver ad gangen.
- Skills er instruktioner, Claude følger. Også her er det Claude, der står for styringen, og svarene fylder op i konteksten. Det, du genbruger, er selve opskriften.
- Workflows er et script, runtimen kører. Nu er det scriptet, der bestemmer, hvad der sker næste gang, og mellemresultaterne bliver i scriptets variabler i stedet for i Claudes kontekst. Det, du genbruger, er hele orkestreringen, og vi taler dusinvis til hundredvis af agenter pr. kørsel.
Og det handler ikke bare om "flere agenter". Når planen ligger i kode, kan du bygge et kvalitetsmønster ind, du kan køre igen og igen: uafhængige agenter, der udfordrer og efterprøver hinandens fund, før noget overhovedet bliver rapporteret. Eller en plan, der lægges fra flere vinkler og vejes op mod hinanden. Det giver et mere troværdigt resultat end ét enkelt gennemløb.
Sådan ser et workflow ud, mens det kører
Når et workflow kører, kan du følge det med kommandoen /workflows. Visningen viser hver fase med sit antal agenter, samlet tokenforbrug og forløbet tid, og du kan dykke ned i en enkelt agent og læse dens prompt, dens seneste værktøjskald og dens resultat. Her er et workflow, der gennemgår en hel FastAPI-flade for uoverensstemmelser på tværs af endpoints:
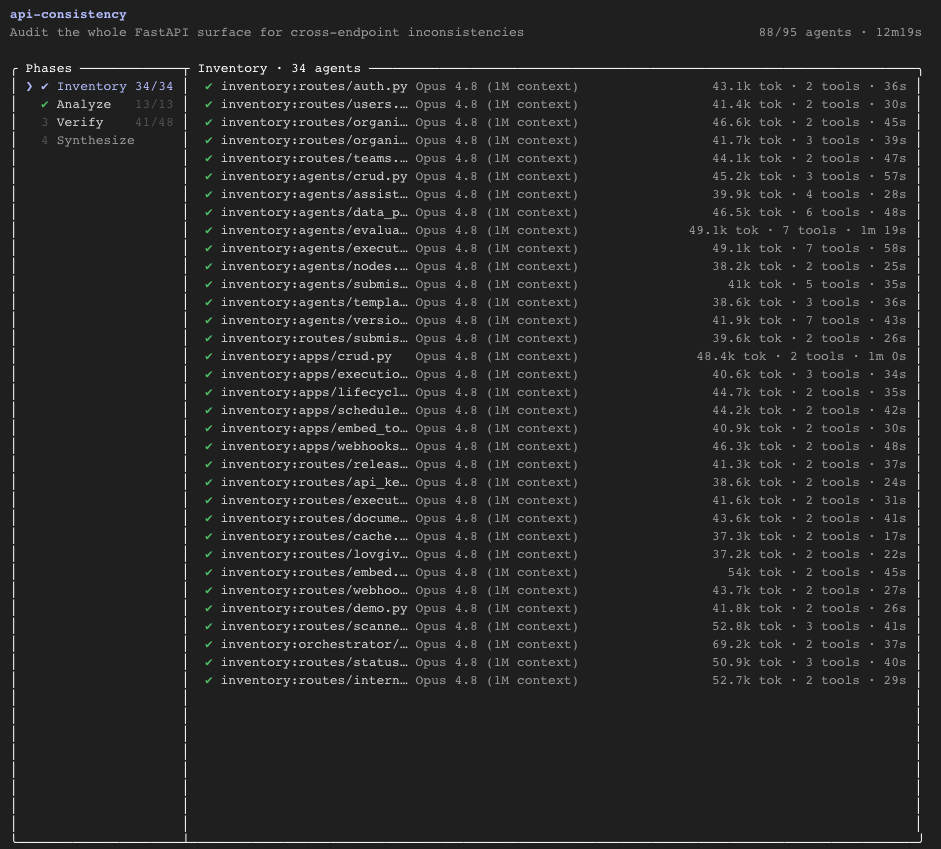
Workflowet hedder api-consistency og består af 95 agenter fordelt på fire faser: Inventory, Analyze, Verify og Synthesize. På skærmbilledet er 88 af de 95 nået i mål efter godt 12 minutter. Hver agent arbejder i sin egen isolerede kontekst på Opus 4.8 med 1M-kontekstvindue og bruger typisk 40-50k tokens. Det er den slags skala, du ikke kan holde i én samtale. Og det er samtidig det semantiske testlag i praksis: ingen kode, bare agenter der hver læser sin del af API'et og krydstjekker, om de stemmer overens.
Hver agent-række viser model, tokenforbrug og antal værktøjer. Læg de tal sammen på tværs af 95 agenter, og du har forklaringen på, hvorfor workflows er dyre. Det ser vi nærmere på længere nede.
Byggeklodserne: agent, parallel, pipeline og phase
Et workflow-script er bare almindeligt JavaScript med nogle få indbyggede funktioner. De fire vigtigste:
agent(prompt)sætter én subagent i gang og giver dig dens svar tilbage. Giver du den et skema, får du et færdigt, valideret objekt i stedet for løs tekst.parallel(opgaver)kører flere ting på én gang og venter, til de alle er færdige (en barriere). Brug den, når du faktisk har brug for alle svarene samtidig.pipeline(emner, trin1, trin2, …)sender hvert emne gennem trinene for sig, uden at vente på de andre. Emne A kan være nået til trin 3, mens emne B stadig hænger i trin 1. Det er som regel det, du vil have, for der spildes ingen ventetid.phase(titel)samler de næste agenter under én fase i fremdriftsvisningen (det er dem, du så som Inventory, Analyze, Verify og Synthesize længere oppe).
Sådan kan et review-workflow se ud i komprimeret form. Det leder efter fejl på flere fronter og lader uafhængige agenter efterprøve hvert fund, før det bliver rapporteret:
Review-workflow (uddrag)
const DIMENSIONER = [
{ key: "bugs", prompt: "Find logiske fejl i ændringerne …" },
{ key: "sikkerhed", prompt: "Find sikkerhedshuller …" },
];
const resultater = await pipeline(
DIMENSIONER,
// Trin 1: review hver dimension
d => agent(d.prompt, { phase: "Review", schema: FUND }),
// Trin 2: lad uafhængige agenter prøve at afkræfte hvert fund
review => parallel(review.fund.map(f => () =>
agent(`Forsøg at afkræfte: ${f.titel}`, { phase: "Verify", schema: DOM })
.then(dom => ({ ...f, dom }))
))
);
const bekraeftede = resultater.flat().filter(f => f.dom?.erReel);Læg mærke til, hvad pipeline gør: "bugs" kan være ved at blive verificeret, mens "sikkerhed" stadig bliver reviewet. Ingen spildtid. Og alle fundene bliver liggende i variablen resultater, så de aldrig fylder noget i din egen samtale.
Kvalitetsmønstrene, der gør workflows til mere end "flere agenter"
Den egentlige grund til at bruge et workflow er ikke farten i sig selv. Det er, at du kan bygge mønstre ind, der gør svaret til at stole på:
- Adversarial verifikation: For hvert fund sætter du flere uafhængige skeptikere på, der hver især prøver at skyde det ned. Et fund overlever kun, hvis de fleste ikke kan afkræfte det. Sådan luger du de fund ud, der lyder plausible, men er forkerte.
- Dommerpanel: Lav flere uafhængige bud fra forskellige vinkler, lad parallelle dommere give point, og byg videre på vinderen. Det slår ét enkelt, itereret forsøg, når der er mange mulige løsninger.
- Gentag til intet nyt dukker op: Når du ikke ved, hvor stor opgaven er (find alle fejl, alle edge cases), bliver agenterne ved med at lede, til flere runder i træk ikke finder noget nyt. Sådan fanger du den lange hale, som et hurtigt "find 10 fejl" ville misse.
- Søgning ad flere spor: Parallelle agenter leder hver på sin måde: efter indhold, efter struktur, efter tid. På den måde misser ingen enkelt vinkel noget.
Det er de mønstre, der adskiller et godt workflow fra bare at råbe på flere agenter, og det er dem, der gør forskellen mellem et svar, man kan stole på, og et, man stadig selv skal kontrollere.
Et overset brug: workflows som et semantisk testlag
Almindelige tests tjekker, at koden gør det, den siger, den gør. Men de kan ikke fortælle dig, om to forskellige artefakter er enige om virkeligheden: passer din OpenAPI-spec til de rigtige route-handlers? Beskriver din README den adfærd, koden faktisk har? Svarer commit-beskeden til det, diffen rent faktisk gør? Det er semantiskespørgsmål. De handler om mening, ikke syntaks, og dem fanger hverken compiler eller unit-test.
Men et workflow kan. Du sætter én læser-agent på hver artefakt, lader den forklare i klar tekst, hvad artefakten betyder, og lader så en dommer-agent holde beskrivelserne op mod hinanden og markere, hvor de ikke passer sammen. Ikke én eneste test eller assertion, bare læsning og sammenligning af mening. Det er et testlag, der lever oven på koden i stedet for inde i den.
Når den vinkel først falder på plads, vælter anvendelserne frem. De er alle sammen svære eller umulige at skrive en almindelig test for:
- Spec ↔ kode ↔ test-triangulering. Tre agenter beskriver henholdsvis kravspec, implementering og tests. Dommeren fanger, hvor testene tester noget, spec'en ikke nævner, eller hvor spec'en lover noget, der aldrig bliver testet.
- Død viden-audit. Find dokumentation, kommentarer, TODO'er og feature flags, der ikke længere passer til virkeligheden. Hver påstand spores til koden, og det forældede markeres.
- Lokaliserings-konsistens. Ikke bare "mangler der nøgler?", men "siger den danske og den engelske tekst det samme?" Én agent pr. sprogpar fanger de oversættelser, som er skredet i betydning.
- Terminologi på tværs af systemet. Hedder det samme begreb det samme i kode, UI-tekster, databaseskema og API? Agenterne kortlægger, hvor ét koncept har tre navne. Det er en stærk kilde til forvirring, både for mennesker og for AI.
- Semantisk regressionstest af en refaktorering. Lad agenter beskrive hvert moduls adfærd i klar tekst før og efter ændringen, og lad en dommer tjekke, at beskrivelserne matcher. En regressionstest helt uden assertions.
- PR-narrativ vs. faktisk diff. Beskriver PR-teksten reelt, hvad ændringen gør? Fang de farlige "står der kun refaktorering, men ændrer faktisk adfærd".
- Konsistens i juridiske dokumenter. Modsiger paragraf 3 paragraf 12? Krydstjek af mening egner sig lige så godt til kontrakter og politikker som til kode. Det er et felt, hvor vi hos syv.ai i forvejen arbejder med dokumentanalyse.
Den fælles indsigt er, at et workflow kan håndhæve konsistens mellem ting, der ikke kan tjekkes med kode, fordi checket handler om mening, og fordi det er billigt at sætte én læser-agent på hver artefakt og lade dem efterprøve hinanden (adversarialt). Det er måske den mest undervurderede grund til at bygge et workflow.
Seks workflows du kan kopiere og køre
De her idéer er nemme at snakke om i det abstrakte, så vi har skrevet dem som rigtige, kørbare scripts i stedet. Hvert script er almindeligt JavaScript, du kan smide i .claude/workflows/ i dit eget repo og køre med /navn. De er med vilje holdt generiske, så de virker på tværs af projekter, og de tager imod argumenter (en sti, et sprogpar, en fil-liste), hvor det giver mening. Sjov detalje: scriptene blev selv skrevet af et workflow, hvor seks agenter lavede hvert sit udkast, og seks andre gik dem efter og rettede til bagefter. Du kan kopiere koden herunder eller hente råfilen under hvert script.
Spec, kode og test-triangulering
Tre agenter beskriver henholdsvis spec, implementering og tests for samme område, hvorefter en dommer triangulerer dem og fanger uoverensstemmelser mellem hvad der loves, og hvad der faktisk testes.
spec-code-test-triangulation.js
export const meta = {
name: "spec-code-test-triangulation",
description: "Three agents describe the spec, the code and the tests for the same area; a judge triangulates the descriptions and catches tests with no spec coverage as well as spec promises with no test coverage.",
phases: [
{ title: "Describe the three sources", detail: "Three parallel agents describe, in plain text, the requirements spec, the implementation and the tests for the area." },
{ title: "Triangulate", detail: "A judge agent cross-checks the three descriptions and finds gaps between spec and tests." }
]
};
// Arguments: path and/or feature name for the area to triangulate.
const area = (typeof args !== "undefined" && (args.path || args.feature || args.area)) || ".";
log(`Triangulating spec, code and tests for area: ${area}`);
// Each agent describes ONLY its own source in plain prose without guessing at the others.
const describe = (source, what) =>
`You are investigating the area "${area}" in this repo. Use Glob/Grep/Read to find ${source}. ` +
`Describe, in clear numbered prose, ${what}; be concrete about each point, cite file paths, and do NOT guess at the other sources.`;
// Phase 1: three independent descriptions at once (barrier).
const grp = { phase: "Describe the three sources", agentType: "Explore" };
const [spec, code, tests] = await parallel([
() => agent(describe("the requirements spec, README, docs or acceptance criteria", "which requirements and promises the spec states"), { ...grp, label: "Spec description" }),
() => agent(describe("the source code / implementation", "which behaviour the code actually implements"), { ...grp, label: "Code description" }),
() => agent(describe("test files and test cases", "which behaviour the tests actually verify"), { ...grp, label: "Test description" })
]);
// Phase 2: the judge cross-checks the three independent descriptions and finds the gaps.
const str = { type: "string" };
const findings = await agent(
`You are the triangulation judge for the area "${area}".\n\n=== SPEC ===\n${spec}\n\n=== CODE ===\n${code}\n\n=== TESTS ===\n${tests}\n\n` +
`Find EXACTLY two kinds of gaps: tests that verify behaviour the spec does not mention ("test_without_spec"), and spec promises that are never tested ("spec_without_test"). ` +
`For each finding: cite in "sources" which source says what, set severity (high/medium/low) and justify briefly. Only include findings you are sure of after cross-checking all three.`,
{ label: "Triangulation judge", phase: "Triangulate", schema: {
type: "object", required: ["findings"], properties: {
findings: { type: "array", items: {
type: "object", required: ["type", "description", "sources", "severity"], properties: {
type: { type: "string", enum: ["test_without_spec", "spec_without_test"] },
description: str, sources: str,
severity: { type: "string", enum: ["high", "medium", "low"] }
} } }
} } }
);
const gaps = findings && Array.isArray(findings.findings) ? findings.findings : []; // the judge may return null if skipped
log(`Triangulation done: ${gaps.length} gap(s) found.`);
return gaps;Sådan virker det: Scriptet tager områdets sti eller feature-navn fra args og bruger parallel() til at køre tre uafhængige Explore-agenter samtidig. Hver beskriver i klar tekst henholdsvis kravspec, implementering og tests uden at gætte på de andre kilder. Bagefter triangulerer en dommer-agent de tre beskrivelser via et JSON-skema og finder to slags huller: tests, der dækker adfærd uden for spec'en, og spec-løfter, der aldrig testes. Styrken ligger i, at de tre kilder beskrives uafhængigt, før dommeren krydstjekker dem, så hvert fund er forankret i, hvad hver kilde faktisk siger.
Hvornår: Brug det, når du vil afdække drift mellem kravspecifikation, kode og tests for et bestemt område eller en feature. Særligt nyttigt før release eller review, hvor du vil vide, om testene dækker det, spec'en lover, og om der testes noget, der aldrig blev specificeret. Hent spec-code-test-triangulation.js
Død viden-audit
Finder dokumentation, kodekommentarer, TODO'er og feature flags og verificerer for hver påstand, om den stadig passer til den faktiske kode.
dead-knowledge-audit.js
export const meta = {
name: "dead-knowledge-audit",
description: "Finds docs, comments, TODOs and feature flags and verifies, per claim, whether they still match the actual code. Stale claims are flagged with file and reasoning.",
phases: [
{ title: "Collect claims", detail: "Three agents extract claims from docs, comments/TODOs and feature flags." },
{ title: "Verify claims", detail: "Each claim is traced to the actual code and judged as holds/stale." },
{ title: "Cross-check stale", detail: "An independent agent double-checks the stale findings before reporting." }
]
};
// Schema for a list of extracted claims
const collectionSchema = {
type: "object",
properties: {
claims: {
type: "array",
items: {
type: "object",
properties: {
source: { type: "string", description: "file:line where the claim appears" },
type: { type: "string", enum: ["doc", "comment", "todo", "flag"] },
claim: { type: "string", description: "what the text claims about the code" }
},
required: ["source", "type", "claim"]
}
}
},
required: ["claims"]
};
// Schema for the verification of a single claim
const verificationSchema = {
type: "object",
properties: {
source: { type: "string" },
claim: { type: "string" },
status: { type: "string", enum: ["holds", "stale", "uncertain"] },
evidenceFile: { type: "string", description: "file(s) that confirm or refute the claim" },
why: { type: "string", description: "short justification" }
},
required: ["source", "claim", "status", "why"]
};
log("Phase 1: Collecting claims from docs, comments/TODOs and feature flags...");
// Three independent collectors run at once (barrier)
const sources = [
{ label: "Doc collector", focus: "README, docs/, markdown and other documentation files" },
{ label: "Comment/TODO collector", focus: "code comments and TODO/FIXME/HACK/XXX markers" },
{ label: "Feature-flag collector", focus: "feature flags, toggles, env-based conditions and their described behaviour" }
];
const collections = await parallel(sources.map((k) => () =>
agent(
`Search this repo with Glob/Grep/Read and extract concrete, checkable claims about the code from ${k.focus}. ` +
`A claim is a statement that CAN have become wrong (e.g. "function X returns Y", "flag Z is active", "the module uses library W"). ` +
`Ignore pure opinions. Give the source as file:line. Return up to 15 of the most risky claims.`,
{ label: k.label, phase: "Collect claims", agentType: "Explore", schema: collectionSchema }
)
));
// Collect all claims into one flat list
const allClaims = collections
.filter(Boolean)
.flatMap((s) => s.claims || [])
.slice(0, 60);
log(`Found ${allClaims.length} claims. Phases 2-3: Verifying and cross-checking per claim...`);
// Pipeline: verify each claim against the code, then cross-check only the stale ones
const results = await pipeline(
allClaims,
// Step 1: trace the claim to the actual code and determine its status
(p) => agent(
`Verify this claim against the ACTUAL code in the repo. Use Grep/Read/Glob to find the relevant code. ` +
`Source: ${p.source}\nType: ${p.type}\nClaim: "${p.claim}"\n` +
`Decide whether the claim still holds ("holds"), is stale ("stale") or cannot be determined ("uncertain"). ` +
`Give the evidence file and a short justification.`,
{ label: `Verify: ${p.source}`, phase: "Verify claims", schema: verificationSchema }
),
// Step 2: independently cross-check ONLY the claims that were marked stale
(v) => v && v.status === "stale"
? agent(
`Another agent marked this claim as STALE. Independently verify against the code whether that is correct. ` +
`Source: ${v.source}\nClaim: "${v.claim}"\nClaimed evidence: ${v.evidenceFile || "unknown"}\nReasoning: ${v.why}\n` +
`Return your own assessment. If you agree, keep status "stale"; otherwise change it to "holds" or "uncertain".`,
{ label: `Cross-check: ${v.source}`, phase: "Cross-check stale", schema: verificationSchema }
)
: v
);
// Consolidate: stale findings (confirmed by cross-check) first, then uncertain ones
const findings = results.filter(Boolean);
const stale = findings.filter((r) => r.status === "stale");
const uncertain = findings.filter((r) => r.status === "uncertain");
log(`Audit done: ${stale.length} confirmed stale, ${uncertain.length} uncertain, ${findings.length - stale.length - uncertain.length} still hold.`);
return {
summary: { total: findings.length, stale: stale.length, uncertain: uncertain.length },
staleFindings: stale,
uncertainFindings: uncertain
};Sådan virker det: Scriptet bruger pipeline-mønstret med en forudgående parallel samlefase. Tre samler-agenter udtrækker samtidig efterprøvbare påstande fra henholdsvis docs, kommentarer/TODO'er og feature flags, hvorefter påstandene flades ud til én liste. Pipelinen kører to trin pr. påstand uden barriere: trin 1 sporer påstanden til den faktiske kode og afgør status (holder, forældet eller usikker), og trin 2 lader en uafhængig agent krydstjekke kun de forældede fund før rapportering. Til sidst konsolideres de bekræftet forældede og de usikre fund med fil og begrundelse.
Hvornår: Brug det, når du vil rydde op i et repos dokumentation, kommentarer, TODO'er og feature flags og finde de påstande, der ikke længere passer til koden. Særligt nyttigt før en større release eller efter længere tids organisk vækst i kodebasen. Hent dead-knowledge-audit.js
Lokaliserings-konsistens (betydningsskred)
Finder locale-filer, danner sprogpar og lader agenter sammenligne betydningen nøgle for nøgle for at markere oversættelser, hvor meningen er skredet.
i18n-meaning-drift.js
export const meta = {
name: "i18n-meaning-drift",
description: "Compares translations across languages key by key and flags meaning drift (not missing keys or formatting).",
phases: [
{ title: "Map locale files", detail: "Find translation files and form language pairs from base and target languages." },
{ title: "Compare meaning per language pair", detail: "One agent per language pair compares the meaning key by key." },
{ title: "Verify drift", detail: "An independent agent cross-checks each flagged drift for false positives." }
]
};
// Args: the base language treated as the source of truth, and optionally specific target languages (comma-separated). Empty = all found.
const baseLang = (args && args.base) ? String(args.base) : "en";
const targetLangsArg = (args && args.target) ? String(args.target).split(",").map(s => s.trim()).filter(Boolean) : null;
// Schema for the mapping: language pairs found in the repo (baseFile -> targetFile).
const mapSchema = { type: "object", required: ["pairs"], properties: { pairs: { type: "array", items: {
type: "object", required: ["targetLang", "baseFile", "targetFile"], properties: {
targetLang: { type: "string", description: "ISO code for the target language" },
baseFile: { type: "string", description: "Absolute path to the base-language file" },
targetFile: { type: "string", description: "Absolute path to the translated file" } } } } } };
// Schema for drift findings per key.
const driftSchema = { type: "object", required: ["findings"], properties: { findings: { type: "array", items: {
type: "object", required: ["key", "baseText", "targetText", "severity", "explanation"], properties: {
key: { type: "string" }, baseText: { type: "string" }, targetText: { type: "string" },
severity: { type: "string", enum: ["critical", "moderate", "minor"], description: "How much the meaning has drifted" },
explanation: { type: "string", description: "Why the meaning differs (not formatting)" } } } } } };
phase("Map locale files");
log(`Searching for locale files; base language = ${baseLang}`);
const map = await agent(
`Find all localisation/translation files in the repo (e.g. in i18n, locales, lang, translations; .json/.yaml/.po/.properties/.arb). ` +
`The base language is "${baseLang}". ${targetLangsArg ? `Limit target languages to: ${targetLangsArg.join(", ")}.` : "Include all target languages found that differ from the base."} ` +
`Form language pairs (baseFile -> targetFile) where both cover the same key set. Use absolute paths.`,
{ schema: mapSchema, agentType: "Explore", phase: "Map locale files", label: "Map locales" }
);
const pairs = (map && map.pairs ? map.pairs : []).filter(p => p && p.targetFile && p.baseFile);
log(`Found ${pairs.length} language pairs. Comparing meaning.`);
// Two-step pipeline: (1) flag drift per pair, (2) let an independent agent verify each flagged drift.
const results = await pipeline(
pairs,
(p) => agent(
`Compare the MEANING key by key between the base file ${p.baseFile} and the translation ${p.targetFile} (target language ${p.targetLang}). ` +
`Read both files. Report ONLY keys where the translated text says something different from the base (wrong number/negation/concept/instruction, omitted or added meaning). ` +
`Ignore pure formatting, punctuation, placeholder and style differences as well as missing keys. Quote both texts.`,
{ schema: driftSchema, phase: "Compare meaning per language pair", label: `Drift ${p.targetLang}` }
),
async (flagged, p) => {
const findings = (flagged && flagged.findings ? flagged.findings : []).filter(f => f && f.key);
if (findings.length === 0) return { targetLang: p.targetLang, targetFile: p.targetFile, findings: [] };
const v = await agent(
`Verify these alleged meaning drifts between ${p.baseFile} (base) and ${p.targetFile} (${p.targetLang}). ` +
`Read the files yourself. Keep ONLY findings where the meaning genuinely differs; remove false positives that are merely formatting, idiom or a correct translation. ` +
`Claims:\n${JSON.stringify(findings, null, 2)}`,
{ schema: driftSchema, phase: "Verify drift", label: `Verify ${p.targetLang}` }
);
return { targetLang: p.targetLang, targetFile: p.targetFile, findings: (v && v.findings ? v.findings : []) };
}
);
// Consolidate into one flat list of verified drifts.
const combined = results.filter(Boolean).flatMap(r => r.findings.map(f => ({ targetLang: r.targetLang, targetFile: r.targetFile, ...f })));
log(`Done: ${combined.length} verified meaning drifts across ${pairs.length} language pairs.`);
return combined;Sådan virker det: Scriptet bruger et tre-faset mønster. Først kortlægger en Explore-agent locale-filerne og danner sprogpar fra basissprog til målsprog med struktureret output. Derefter kører en to-trins pipeline pr. sprogpar, hvor trin 1 markerer betydningsskred nøgle for nøgle, og trin 2 lader en uafhængig agent krydstjekke og fjerne falske positive. Til sidst konsolideres de verificerede fund til én flad liste. Basis- og målsprog kan styres via args.
Hvornår: Brug det, når du har flersprogede oversættelsesfiler og vil vide, om den oversatte tekst faktisk betyder det samme som basisteksten. Det fanger betydningsskred (forkerte tal, negationer, udeladt mening), ikke manglende nøgler eller formateringsforskelle. Hent i18n-meaning-drift.js
Terminologi på tværs af systemet
Kortlægger hvad de centrale domænebegreber hedder i hvert lag (kode, UI, DB, API) og markerer, hvor ét koncept optræder under flere navne.
terminology-consistency.js
export const meta = {
name: "terminology-consistency",
description: "Maps the names of key domain concepts in each layer (code, UI strings, DB schema, API) and finds where one concept has multiple names.",
phases: [
{ title: "Map layers", detail: "One agent per layer finds concept names in code, UI, DB schema and API." },
{ title: "Find collisions", detail: "A judge collects the map and cross-checks for concepts with multiple names." }
]
};
// Schema for one layer's map (name, covered concept, examples) and for the judge's collision findings
const termItem = { type: "object", required: ["name", "meaning", "examples"], properties: { name: { type: "string" }, meaning: { type: "string" }, examples: { type: "array", items: { type: "string" } } } };
const layerSchema = { type: "object", required: ["layer", "terms"], properties: { layer: { type: "string" }, terms: { type: "array", items: termItem } } };
const collisionItem = { type: "object", required: ["concept", "names", "severity", "recommendation"], properties: { concept: { type: "string" }, names: { type: "array", items: { type: "string" } }, severity: { type: "string", enum: ["high", "medium", "low"] }, recommendation: { type: "string" } } };
const judgeSchema = { type: "object", required: ["collisions"], properties: { collisions: { type: "array", items: collisionItem } } };
// The four layers, each mapped by an independent agent
const layers = [
{ name: "code", hint: "class, function, variable and type names in the source code" },
{ name: "UI strings", hint: "labels, button text, headings and translations in frontend/i18n files" },
{ name: "DB schema", hint: "table and column names in migrations, ORM models and SQL" },
{ name: "API/endpoints", hint: "route paths, request/response fields and DTOs in the API layer" }
];
log("Mapping terminology across " + layers.length + " layers in parallel ...");
const map = (await parallel(layers.map((l) => () => agent(
"You are mapping TERMINOLOGY in the '" + l.name + "' layer (" + l.hint + ") of this repo. Use Glob/Grep/Read to find the names of the key DOMAIN CONCEPTS (entities, resources, statuses, roles); ignore pure technical plumbing. For each concept: give the concrete name, which concept it covers, and 1-3 concrete examples (file:line). Only report names you have actually seen.",
{ schema: layerSchema, label: "Map: " + l.name, phase: "Map layers", agentType: "Explore" })))).filter(Boolean);
log("Judge cross-checks the layers and finds naming collisions ...");
// The judge verifies it really is the same concept before reporting (quality check)
const judgment = await agent(
"You are the TERMINOLOGY JUDGE. Below are concept maps from four layers as JSON:\n\n" + JSON.stringify(map, null, 2) + "\n\nFind COLLISIONS: one and the same domain concept that appears under DIFFERENT names across layers (e.g. 'customer' in UI, 'client' in code, 'account' in DB). Verify it really is the same concept before reporting; ignore plain synonyms that cause no confusion. State the severity and recommend one canonical name per collision.",
{ schema: judgeSchema, label: "Judge: collisions", phase: "Find collisions" });
const order = { high: 0, medium: 1, low: 2 }; // sort by severity
const findings = (judgment?.collisions ?? []).sort((a, b) => (order[a.severity] ?? 3) - (order[b.severity] ?? 3));
log("Done. Found " + findings.length + " terminology collision(s).");
return { collisions: findings, layersMapped: map.map((k) => k.layer) };Sådan virker det: Scriptet definerer fire lag (kode, UI-strenge, DB-skema og API) og kører dem gennem parallel(), så hver agent kortlægger sit lags begrebsnavne samtidigt bag en barriere; fejlende agenter frafiltreres med .filter(Boolean). Hvert lag-resultat valideres mod et JSON-skema med navn, betydning og eksempler. Bagefter får én dommer-agent hele kortet som JSON og krydstjekker lagene for at finde koncepter, der optræder under flere navne, før den rapporterer. Til sidst sorteres kollisionerne efter alvor og returneres samlet.
Hvornår: Brug det, når du vil sikre, at samme domænebegreb hedder det samme i kode, UI, database og API. Især nyttigt i ældre eller hurtigt voksende kodebaser, hvor begreber som customer, client og account er drevet fra hinanden. Hent terminology-consistency.js
Semantisk regressionstest af en refaktorering
For hvert berørt modul beskriver agenter adfærden før og efter ændringen, og en dommer markerer den adfærd, der utilsigtet har ændret sig.
semantic-refactor-regression.js
export const meta = {
name: "semantic-refactor-regression",
description: "Assertion-free regression test: describes each affected module's behaviour before and after a refactor and lets a judge flag unintended changes.",
phases: [
{ title: "Describe behaviour before and after", detail: "Two agents describe the old and new module's behaviour in plain text." },
{ title: "Judge semantic deviations", detail: "A judge compares them and flags unintended behaviour changes." }
]
};
// The list of affected files/modules is taken from args (comma- or space-separated).
const files = (typeof args === "string" ? args : (args?.files || args?.join?.(" ") || ""))
.split(/[\s,]+/).map(s => s.trim()).filter(Boolean);
log(`Semantic regression test of ${files.length} affected module(s).`);
// Schema for behaviour descriptions.
const behaviorSchema = { type: "object", required: ["module", "behavior"], properties: {
module: { type: "string" },
behavior: { type: "array", items: { type: "string" }, description: "Observable behaviour points in plain text (in/output, side effects, errors)." }
}};
// Schema for the judge's verdict.
const verdictSchema = { type: "object", required: ["module", "deviations"], properties: {
module: { type: "string" },
deviations: { type: "array", items: { type: "object", required: ["description", "severity", "unintended"], properties: {
description: { type: "string" },
severity: { type: "string", enum: ["critical", "moderate", "cosmetic"] },
unintended: { type: "boolean", description: "True if the change appears unintended (a regression)." }
}}}
}};
// Pipeline per module: the first step describes both BEFORE and AFTER in parallel, the second step judges.
const results = await pipeline(files,
(_, file) => parallel([
() => agent(`Describe, in plain text, the OBSERVABLE behaviour of '${file}' BEFORE the change. Use Bash to run 'git show HEAD~1:${file}' (or the most recent version present in history) and read the contents. Cover input/output, side effects, error handling and edge cases. No assertions, only a behaviour description.`,
{ label: `before: ${file}`, phase: "Describe behaviour before and after", agentType: "Explore", schema: behaviorSchema }),
() => agent(`Describe, in plain text, the OBSERVABLE behaviour of '${file}' AFTER the change. Read the current file in the working tree with Read. Cover input/output, side effects, error handling and edge cases. No assertions, only a behaviour description.`,
{ label: `after: ${file}`, phase: "Describe behaviour before and after", agentType: "Explore", schema: behaviorSchema })
]),
([before, after], file) => {
// Cross-check: an independent judge compares the two descriptions.
if (!before || !after) return null;
return agent(`You are the semantic judge for the module '${file}'. Compare BEFORE and AFTER and flag only behaviour that has changed unintentionally (a regression). A pure refactor should preserve behaviour. Verify doubtful cases against the actual code with Read/Grep before reporting.\n\nBEFORE:\n${JSON.stringify(before)}\n\nAFTER:\n${JSON.stringify(after)}`,
{ label: `verdict: ${file}`, phase: "Judge semantic deviations", schema: verdictSchema });
}
);
// Collect the flagged regressions into one consolidated list.
const verdicts = results.filter(Boolean);
const regressions = verdicts.flatMap(d => (d.deviations || [])
.filter(a => a.unintended).map(a => ({ module: d.module, ...a })));
log(`Done. ${regressions.length} possible regression(s) found across ${verdicts.length} module(s).`);
return { modulesReviewed: verdicts.length, regressions, allVerdicts: verdicts };Sådan virker det: Scriptet tager listen af berørte filer fra args og kører en pipeline pr. modul. Første trin beskriver parallelt modulets adfærd før ændringen (via 'git show HEAD~1' i Bash) og efter ændringen (working tree) med to uafhængige Explore-agenter. Andet trin er en dommer, der sammenligner de to klartekst-beskrivelser, kun markerer utilsigtede afvigelser og krydstjekker tvivlstilfælde mod den faktiske kode før rapportering. Alt struktureret output styres af JSON-skemaer, og til sidst konsolideres alle markerede regressioner i én liste.
Hvornår: Brug det efter en refaktorering, hvor du ikke har dækning fra en testsuite og vil fange utilsigtede adfærdsændringer. Velegnet, når du har en konkret liste af berørte moduler og vil have en hurtig, assertionsfri semantisk regressionskontrol. Hent semantic-refactor-regression.js
PR-narrativ vs. faktisk diff
Sammenholder hvad en PR- eller commit-beskrivelse påstår, med hvad den faktiske git-diff reelt ændrer, og fanger farlige uoverensstemmelser.
pr-narrative-vs-diff.js
export const meta = {
name: "pr-narrative-vs-diff",
description: "Compares the PR/commit narrative with the actual diff and catches discrepancies, especially hidden behaviour changes described as a pure refactor.",
phases: [
{ title: "Collect narrative and diff", detail: "Extract claims from the description and facts from the actual diff in parallel." },
{ title: "Judge discrepancies", detail: "Cross-check narrative against diff and find deviations, especially hidden behaviour changes." }
]
};
// The PR/diff reference is taken as an argument; falls back to the most recent commit range.
const ref = (typeof args !== "undefined" && args && args.ref) ? args.ref : "HEAD~1..HEAD";
log(`Analysing PR/diff reference: ${ref}`);
// Schema for the claimed narrative and for the actual diff.
const narrativeSchema = { type: "object", required: ["claims"], properties: { claims: { type: "array", items: { type: "object", required: ["claim", "type"], properties: { claim: { type: "string" }, type: { type: "string", enum: ["refactor", "bugfix", "new-feature", "behavior-change", "other"] } } } } } };
const diffSchema = { type: "object", required: ["changes"], properties: { changes: { type: "array", items: { type: "object", required: ["description", "affectsBehavior"], properties: { file: { type: "string" }, description: { type: "string" }, affectsBehavior: { type: "boolean" } } } } } };
// Two independent readers run in parallel (barrier): one sees only the narrative, one sees only the diff.
const [narrative, diff] = await parallel([
() => agent(`Read ONLY the PR/commit message for reference '${ref}'. Use Bash: 'git log ${ref} --format=%B' and optionally 'gh pr view'. Extract each claimed change and classify its type. Do NOT inspect the code.`, { label: "Narrative reader", phase: "Collect narrative and diff", agentType: "Explore", schema: narrativeSchema }),
() => agent(`Read ONLY the actual diff for reference '${ref}' via Bash 'git diff ${ref}'. Describe objectively what each change does, and mark whether it changes runtime behaviour (not just structure). Do NOT read the description.`, { label: "Diff reader", phase: "Collect narrative and diff", agentType: "Explore", schema: diffSchema })
]);
// The judge cross-checks the two independent descriptions and finds dangerous discrepancies.
const judgeSchema = { type: "object", required: ["findings", "verdictSummary"], properties: { findings: { type: "array", items: { type: "object", required: ["severity", "description"], properties: { severity: { type: "string", enum: ["critical", "high", "medium", "low"] }, description: { type: "string" }, category: { type: "string", enum: ["hidden-behavior-change", "unmentioned-change", "claim-without-coverage", "ok"] } } } }, verdictSummary: { type: "string" } } };
const verdict = await agent(`You are the judge. Compare the CLAIMED narrative with the ACTUAL diff.\nNARRATIVE: ${JSON.stringify(narrative)}\nACTUAL DIFF: ${JSON.stringify(diff)}\nFind discrepancies. Prioritise the dangerous pattern: the narrative says "refactor only", but the diff actually changes behaviour (mark as critical/high). Also find unmentioned changes and claims without coverage in the diff.`, { label: "Judge", phase: "Judge discrepancies", schema: judgeSchema });
// Consolidate and report the combined findings to the user.
log(`Verdict (${(verdict.findings || []).length} findings): ${verdict.verdictSummary}`);
for (const f of (verdict.findings || [])) log(`- [${f.severity}] ${f.description}`);Sådan virker det: Scriptet kører to uafhængige Explore-agenter parallelt bag en barriere: den ene læser kun PR-/commit-beskrivelsen og udtrækker de påståede ændringer, den anden læser kun den faktiske git-diff via Bash og beskriver, hvad der reelt sker. Begge returnerer struktureret JSON via et skema. En dommer-agent krydstjekker derefter de to uafhængige beskrivelser og klassificerer uoverensstemmelser efter alvor, med særligt fokus på skjulte adfærdsændringer maskeret som refaktorering.
Hvornår: Brug det ved PR-review, når du vil verificere, at beskrivelsen ærligt afspejler ændringen, før du godkender. Særligt værdifuldt, når en PR påstår "ren refaktorering", men kan skjule funktionelle ændringer. Hent pr-narrative-vs-diff.js
Husk lige, at hvert af de her scripts sætter en håndfuld agenter i gang eller flere, så de er til de tunge opgaver, ikke de hurtige opslag. Kør dem med omtanke, og kig på /model først, hvis du vil holde forbruget nede. Til gengæld får du et konsistens-tjek, du umuligt kunne skrive som en almindelig test.
Hvorfor workflows er så gode
Til de rigtige opgaver giver et workflow dig tre ting, du ikke får i en almindelig samtale:
- Skala uden at sprænge konteksten. Fordi mellemresultaterne bliver i scriptet, kan du tygge dig igennem hundredvis af filer eller kilder uden at fylde Claudes kontekstvindue op. Det er forskellen på at nå hele vejen rundt om en kodebase og at løbe tør for plads halvvejs.
- Indbygget kvalitetskontrol. Mønstrene ovenfor giver mere troværdige svar end ét enkelt forsøg. Til research vil det sige, at de påstande, der ikke kan klare et krydstjek, allerede er sorteret fra, inden rapporten lander hos dig.
- Gentagelighed. Når en kørsel rammer plet, kan du gemme scriptet som en kommando. Et review, du kører på hver branch, gør så det samme hver gang, og du kan læse præcis, hvad det gør.
Det nemmeste sted at se det i praksis er det indbyggede /deep-research. Det spreder søgningerne ud på flere vinkler, henter kilderne, krydstjekker dem og samler det hele i en rapport med henvisninger. Imens er din session fri til andet, og du får én færdig rapport til sidst i stedet for en lang tur-for-tur-udskrift.
Hvorfor det er dyrt
Så til prisen. Et workflow sætter mange agenter i gang, og hver af dem har sit eget kontekstvindue. Hvor en almindelig samtale-tur koster ét sæt tokens, koster et workflow summen af dem alle. Forbruget lægges ikke bare oven i din samtale, det multipliceres.
Tallene er ikke sat højt for effektens skyld: api-consistency-kørslen ovenfor brugte omkring 6 millioner tokens i alt på sine 95 agenter. Til sammenligning bruger en almindelig samtale-tur sjældent mere end nogle få tusinde. Det er en faktor flere hundrede, og det er for én enkelt kørsel. Et workflow er desuden bundet af to grænser, der siger noget om skalaen:
- Op til 16 agenter samtidigt (færre på maskiner med få CPU-kerner). Loftet er der for at begrænse, hvor meget af maskinens ressourcer kørslen lægger beslag på. Resten af agenterne står i kø og kører, efterhånden som der bliver plads.
- Op til 1.000 agenter i alt pr. kørsel, som er en sikring mod løbske løkker, men også en påmindelse om, hvor stort forbruget kan blive.
Kørsler tæller med i din plans forbrug og rate limits som enhver anden session. Og slår du ultracode til (/effort ultracode), planlægger Claude et workflow for hver større opgave. Én anmodning kan blive til flere workflows i træk (ét til at forstå koden, ét til at lave ændringen, ét til at verificere). Det giver bedre resultater, men hver anmodning bruger flere tokens og tager længere tid.
Sådan holder du prisen nede
- Tjek
/modelfør en stor kørsel. Hver agent bruger din sessions model, medmindre scriptet ruter en fase til en anden. Skifter du normalt til en mindre model til rutinearbejde, så sørg for, at den er valgt inden. - Bed om en mindre model til de lette faser. Når du beskriver opgaven, kan du bede Claude om at bruge en billigere model til de trin, der ikke kræver den stærkeste.
- Stop kørsler, der løber løbsk. Du kan altid stoppe et igangværende workflow fra
/workflowsuden at miste det arbejde, der allerede er færdigt. - Reservér workflows til de tunge opgaver. Den bedste omkostningskontrol er at lade være med at bruge et workflow til noget, en almindelig samtale klarer fint.
Hvornår skal du bruge et workflow, og hvornår ikke?
Tommelfingerreglen er enkel: tag et workflow frem, når en opgave kræver flere agenter, end én samtale kan holde styr på, eller når du vil have orkestreringen som et script, du kan læse og køre igen. For eksempel:
- En kodebase-dækkende fejljagt på tværs af mange moduler.
- En migrering på 500 filer, hvor hver fil transformeres og verificeres.
- Et research-spørgsmål, hvor kilder skal krydstjekkes mod hinanden.
- En svær plan, der er værd at udarbejde fra flere uafhængige vinkler, før du vælger én.
Men til en enkelt, ligetil opgave, et hurtigt opslag eller en lille rettelse er et workflow helt forkert valg, for det er bare langsommere og dyrere. Der kommer du hurtigere i mål ved at lade Claude arbejde direkte, måske med et par skills eller en enkelt subagent.
Sådan kommer du i gang
- Skriv "workflow" i din prompt. Så skriver Claude et script til opgaven i stedet for at arbejde tur for tur. Claude Code beder om din godkendelse og viser de planlagte faser, før noget kører.
- Prøv
/deep-research. Det indbyggede workflow er den hurtigste måde at se, hvordan det hele fungerer på et rigtigt spørgsmål. - Følg kørslen med
/workflows. Vælg en kørsel for at se faser, agenter, tokenforbrug og forløbet tid, og for at stoppe, pause eller genoptage den. - Gem det, der virker. Fra
/workflowskan du gemme en kørsels script som en/kommando, enten i projektet (delt via git) eller personligt.
Dynamiske workflows er i research preview og kræver Claude Code v2.1.154 eller nyere. De virker på alle betalte planer, via API og på Amazon Bedrock, Google Cloud Vertex AI og Microsoft Foundry. På Pro slås de til under Dynamic workflows i /config, og de kan slås helt fra for både den enkelte og hele organisationen.
Hvad betyder workflows for danske virksomheder?
Workflows flytter Claude fra at være en assistent, der hjælper med én ting ad gangen, til at være noget, der kan tage en hel, tung opgave på sig: en sikkerhedsgennemgang af hele kodebasen, en migrering, der ellers ville tage en udvikler en uge, eller en grundig research-rapport med krydstjekkede kilder. For et team er gevinsten, at den slags arbejde bliver gentageligt og revisérbart. Orkestreringen ligger i et script, I kan læse og versionere som al anden kode.
Men gevinsten følges af en reel omkostning, og den skal styres bevidst. Det er præcis den afvejning, vi arbejder med hos syv.ai: hvornår en multi-agent-tilgang faktisk betaler sig, hvordan I sætter rammerne for forbruget, og hvordan workflows spiller sammen med jeres egne modeller, data og MCP-integrationer. Overvejer I at tage workflows i brug i praksis, så tag fat i os.
Ofte stillede spørgsmål
Hvad er forskellen på et workflow, en subagent og en skill?
Forskellen er, hvem der holder planen. Med en subagent eller en skill er Claude orkestratoren: den beslutter tur for tur, hvad der skal køre næste gang, og hvert mellemresultat lander i Claudes kontekstvindue. Et workflow flytter planen ind i et script. Scriptet holder løkken, forgreningerne og mellemresultaterne, så Claudes kontekst kun indeholder det færdige svar. Det er det, der gør det muligt at koordinere dusinvis til hundredvis af agenter i én kørsel.
Hvordan starter jeg et workflow i Claude Code?
Den enkleste måde er at skrive ordet "workflow" et sted i din prompt. Så skriver Claude et script til opgaven i stedet for at arbejde tur for tur. Du kan også køre det indbyggede /deep-research, eller slå ultracode til med /effort ultracode, så Claude selv planlægger et workflow for hver større opgave. Inden et workflow kører, beder Claude Code om din godkendelse og viser de planlagte faser.
Hvorfor bruger workflows så mange tokens?
Fordi et workflow starter mange agenter, og hver agent har sit eget kontekstvindue. Hvor en almindelig samtale-tur koster ét sæt tokens, koster et workflow summen af alle agenternes forbrug. Et rigtigt eksempel: api-consistency-kørslen brugte omkring 6 millioner tokens på sine 95 agenter fordelt på fire faser. En kørsel kan starte op til 1.000 agenter. Forbruget tæller med i din plans forbrug og rate limits som enhver anden session.
Kan jeg styre, hvor meget et workflow koster?
Ja. Tjek /model før en stor kørsel, hvis du normalt skifter til en mindre model til rutineopgaver. Hver agent bruger din sessions model, medmindre scriptet ruter en fase til en anden. Du kan bede Claude om at bruge en mindre model til de faser, der ikke kræver den stærkeste. Og du kan altid stoppe en igangværende kørsel fra /workflows uden at miste det arbejde, der allerede er færdigt.
Hvornår bør jeg IKKE bruge et workflow?
Til en enkelt, lineær opgave, et hurtigt opslag eller en lille ændring er et workflow det forkerte værktøj. Det er både langsommere og dyrere end bare at lade Claude løse opgaven direkte. Workflows giver mening, når en opgave kræver flere agenter, end én samtale kan koordinere: en kodebase-dækkende fejljagt, en migrering på tværs af mange filer, eller research, hvor kilder skal krydstjekkes mod hinanden.
Er dynamiske workflows tilgængelige for alle?
Dynamiske workflows er i research preview og kræver Claude Code v2.1.154 eller nyere. De er tilgængelige på alle betalte planer, med API-adgang og på Amazon Bedrock, Google Cloud Vertex AI og Microsoft Foundry. På Pro slås de til via /config. De kan slås fra for både den enkelte og hele organisationen via settings.