
Plapre er en open source tekst-til-tale-model for dansk. Den kan generere naturligt klingende tale fra tekst, klone stemmer ud fra korte lydklip, og køre helt lokalt uden at sende data til eksterne tjenester. I dette indlæg gennemgår vi den tekniske arkitektur bag Plapre: fra datasæt til træning til inferens.
Grundidéen
Plapre bruger en sprogmodel (LLM) til at oversætte tekst til lydtokens. Det er den samme type model, man kender fra ChatGPT, bare rettet mod at forudsige lyd i stedet for tekst. Konkret tager modellen en dansk sætning som input og genererer en sekvens af diskrete lydtokens, som derefter afkodes til en lydbølge af en vocoder.
Hele pipelinen ser sådan ud:
Tekst → BPE-tokenisering → Sprogmodel → Lydtokens → Kanade vocoder → Lydbølge (24kHz WAV)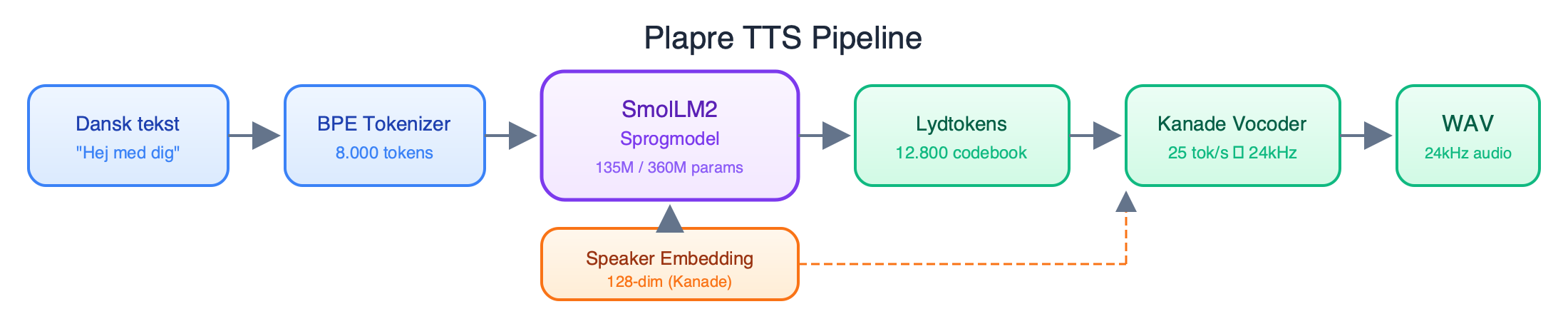
Datasæt
Vi træner på to store danske taledatasæt:
NST-DA (alexandrainst/nst-da) er det største, med cirka 237.000 samples af oplæst dansk tale. Det dækker mange forskellige talere og giver modellen et bredt fundament.
FTSpeech er et datasæt baseret på Folketingets taler: naturlig, spontan dansk tale med stor variation i tonefald og tempo.
Tilsammen giver det over 1,3 millioner træningssamples. Hvert sample består af en tekst og det tilhørende lydklip.
Kanade: Fra lyd til tokens
For at en sprogmodel kan arbejde med lyd, skal lyden repræsenteres som diskrete tokens, ligesom ord repræsenteres som BPE-tokens i en tekstmodel.
Vi bruger Kanade som lydtokenizer. Kanade er en neural audio-codec, der komprimerer lyd til en sekvens af tokens med en rate på 25 tokens per sekund. Dens codebook indeholder 12.800 unikke tokens, og den opererer ved 24kHz samplerate.
Når Kanade encoder et lydklip, producerer den to ting:
- Content tokens: en sekvens af heltal (0-12.799) der repræsenterer selve lydens indhold. Et 5-sekunders klip giver ca. 125 tokens.
- En global embedding: en 128-dimensionel vektor der fanger talerens stemmekarakteristika og stil.
Denne opdeling er central for Plapre: content tokens bærer hvad der siges, mens den globale embedding bærer hvordan det lyder (stemmen, tonefaldet, den akustiske signatur).
Forprocessering
For hvert sample i datasættet:
- Lyden resamples til 24kHz og konverteres til mono
- Vi filtrerer klip til mellem 1 og 15 sekunders varighed
- Kanade encoder lyden og producerer content tokens + global embedding
- Vi klipper tokens til
duration + 0.3 sekunder × 25 tokens/sfor at fjerne artefakter fra Kanade-encoderen
Resultatet gemmes som en parquet-fil med kolonnerne: speaker_id, text, audio_tokens, global_embedding og duration.
Tokenizer: Ét samlet vokabularium
Sprogmodellen skal håndtere både tekst og lyd i ét samlet vokabularium. Vi bygger en custom tokenizer med tre lag:
- BPE-tokens (8.000): dansk tekst, trænet på datasættets transskriptioner
- Separatorer (2):
<text>og<audio>til at markere sektionsgrænser - Lydtokens (12.800):
<audio_0>til<audio_12799>, ét per Kanade codebook-entry
Total: 20.802 tokens.
Det er vigtigt at hvert lydtoken er et atomisk token i vokabulariet. Det må ikke split-tokeniseres af BPE-tokenizeren. Hvis <audio_4523> blev delt op i sub-tokens, ville modellen miste evnen til at lære lydmønstre. Derfor tilføjes alle lydtokens som specielle tokens.

Sekvensformat
Hvert træningseksempel formateres som én sekvens:
[speaker_emb] <text> Hej, hvordan har du det? <audio> <audio_42> <audio_1337> ... <audio_99> <eos>[speaker_emb]: talerens 128-dim embedding, projiceret til modellens skjulte dimension via et lineært lag og indsat som det første "token"<text>: separator der markerer starten på tekst- BPE-tokens: den danske tekst tokeniseret
<audio>: separator der markerer starten på lyd- Lydtokens: Kanade content tokens, formateret som
<audio_N> <eos>: slut-på-sekvens
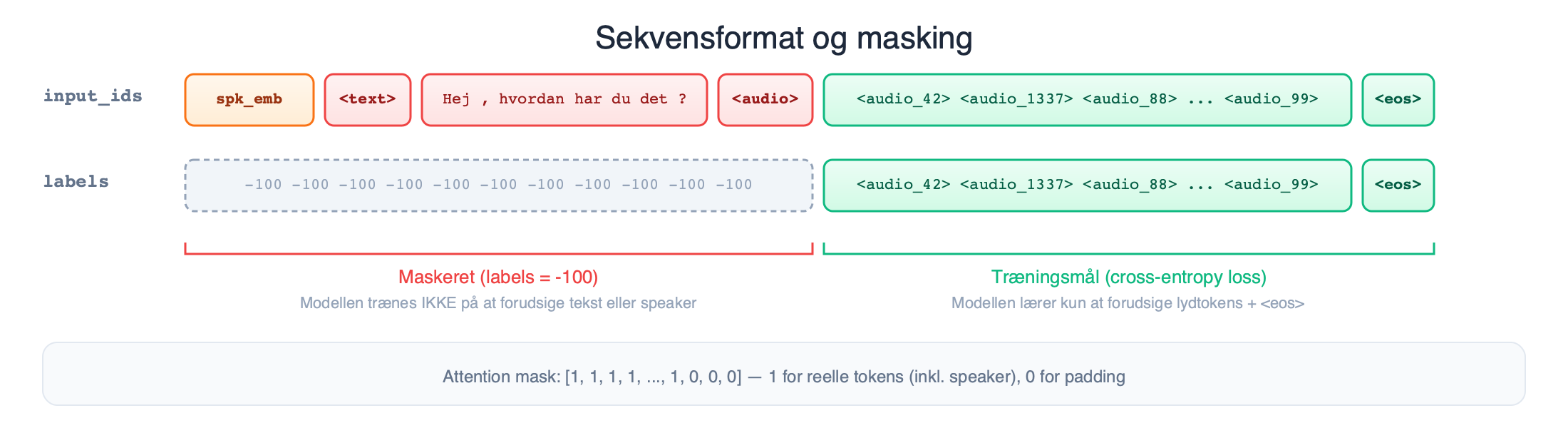
Masking: Hvad modellen trænes på
Vi maskerer labels strategisk, så modellen kun trænes på at forudsige de rigtige dele af sekvensen.
I labels-arrayet sættes -100 (PyTorchs ignore-index) for:
- Speaker-positionen: det projicerede embedding-token. Modellen skal ikke forudsige denne; den er givet som input.
- Tekstdelen:
<text>, BPE-tokens og<audio>-separatoren. Modellen skal ikke lære at forudsige teksten, den er givet. - Padding: fyld-tokens for at gøre alle sekvenser lige lange.
Det eneste modellen reelt trænes på er altså: lydtokens + <eos>.
Det giver intuitiv mening: givet en tekst og en talerstemme, skal modellen lære at generere den tilhørende lyd. Teksten er kontekst, ikke mål.
Basemodel
Vi tager udgangspunkt i SmolLM2, Hugging Faces serie af kompakte sprogmodeller. Plapre Pico bruger 135M-varianten, Plapre Nano bruger 360M.
Da SmolLM2 har et vokabularium på 49.152 tokens og vi kun bruger 20.802, bygger vi en ny model:
- Indlæs SmolLM2's config og sæt
vocab_size = 20.802 - Opret en ny model med den tilpassede config
- Kopiér alle transformer-vægte fra den originale model (attention, FFN, layer norms)
- Spring embed_tokens og lm_head over (de har forkert størrelse)
- Initialisér de nye embeddings med
N(mean, std)fra de originale embedding-vægte
Transformer-lagene beholder altså al den sprogforståelse SmolLM2 har lært under sin pretraining. Kun embedding-tabellen er ny og skal læres fra bunden.
Talerkonditionering
Talerens stemme injiceres via en simpel lineær projektion:
speaker_proj = nn.Linear(128, hidden_size) # 128 → 576 (Pico) eller 960 (Nano)Under træning og inferens projiceres den 128-dimensionelle Kanade-embedding til modellens skjulte dimension og indsættes som det allerførste token i sekvensen, før <text>. Modellen "ser" dette token via attention og kan konditionere hele sin generation på talerens stemme.
Det er hele mekanismen. Ingen cross-attention, ingen adapter-moduler. Bare ét ekstra token i starten af sekvensen.
Træning
Træningen bruger en standard autoregressiv sprogmodellerings-loop med nogle tilpasninger:
- Effektiv batchstørrelse: 32
- Learning rate: 5e-3
- Scheduler: Cosine med 5% warmup
- Præcision: bfloat16
- Epoker: 3
- Optimizer: AdamW (weight_decay=0.01)
Vi bruger torch.amp.autocast("cuda", dtype=bfloat16) for mixed-precision træning, gradient clipping med max norm 1.0, og evaluerer hver halve epoke.
Tab-funktionen er standard cross-entropy, men vi tracker separate metrikker for lydtokens: audio_loss (cross-entropy kun på lydtokens) og audio_accuracy (top-1 nøjagtighed på lydtokens). Det giver et klarere billede af, om modellen faktisk lærer at generere lyd, uafhængigt af eventuelle tekst-tabs.
Inferens
Ved inferens kører pipelinen i den modsatte retning:
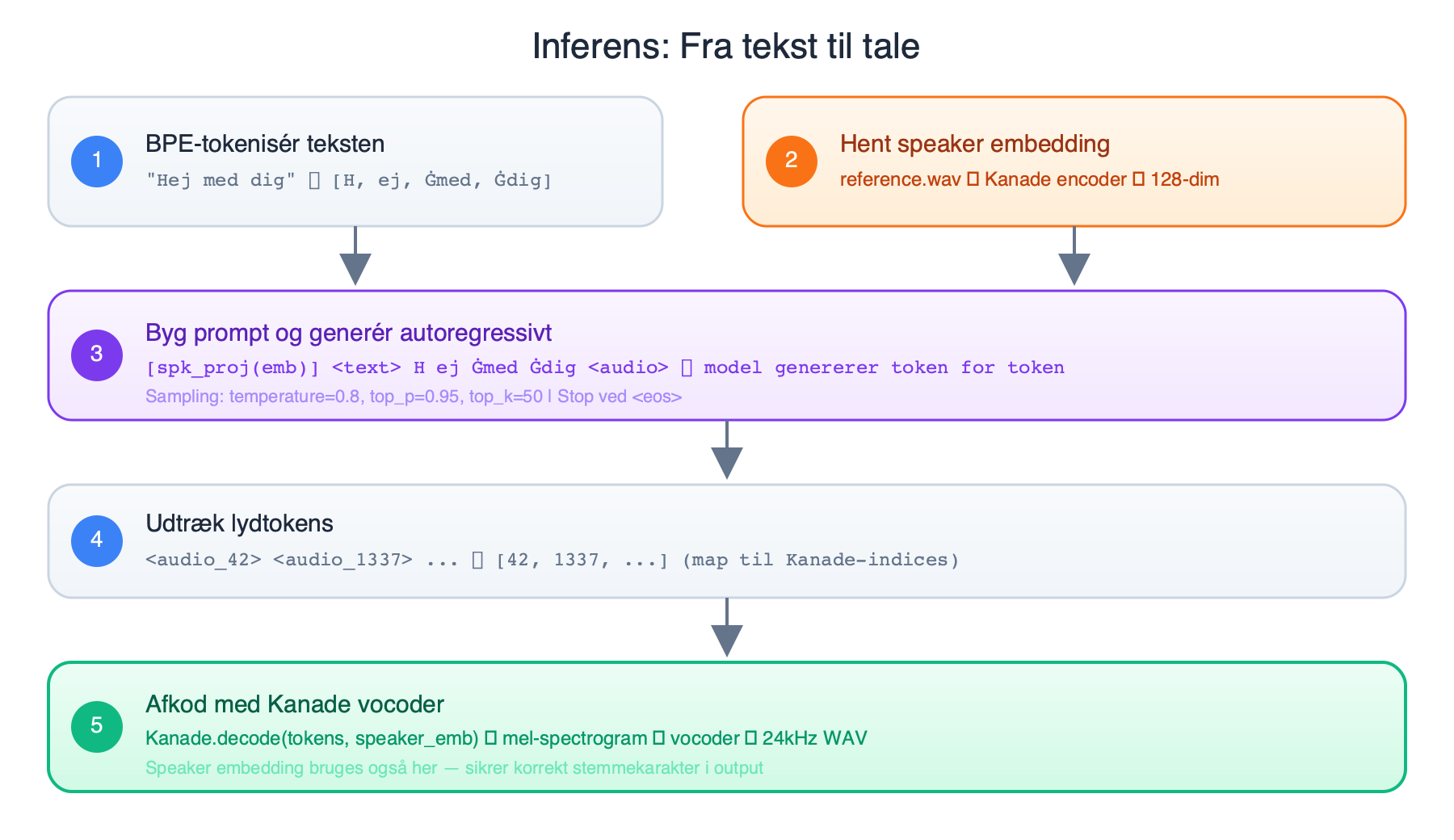
1. Byg prompt
Inputteksten BPE-tokeniseres og formateres som prompt:
[speaker_emb] <text> BPE-tokens <audio>Modellen får altså teksten og taler-embeddinget og skal selv generere resten: lydtokensene.
2. Speaker embedding
Hvis man vil klone en stemme, indlæses et reference-lydklip (WAV), og Kanade encoder udtrækker den 128-dim globale embedding. Denne projiceres og indsættes som det første token.
Uden et reference-klip bruges en nul-vektor, hvilket giver en "neutral" stemme, eller man kan vælge en af de indbyggede talere.
3. Autoregressiv generering
Modellen genererer tokens ét ad gangen med sampling (temperature, top-p, top-k). Den stopper når den producerer <eos>.
4. Afkodning
De genererede lydtokens (f.eks. <audio_42>, <audio_1337>, ...) mappes tilbage til Kanade-indices (42, 1337, ...) og sendes gennem Kanades vocoder sammen med speaker-embeddinget. Vocoderen producerer en 24kHz lydbølge.
Det er vigtigt at vocoderen også modtager speaker-embeddinget, da det sikrer at den rekonstruerede lyd har den rigtige stemmekarakter, ikke bare det rigtige indhold.
Stemmekloning
Stemmekloning i Plapre kræver ingen finetuning. Det hele sker via Kanades globale embedding:
- Indlæs et kort lydklip af den stemme man vil klone (10-30 sekunder anbefales)
- Kør det gennem Kanades encoder → 128-dim embedding
- Brug dette embedding til generation
from plapre import Plapre
tts = Plapre("syvai/plapre-nano")
tts.speak("Hej med dig.", output="cloned.wav", speaker_wav="reference.wav")Kvaliteten af kloningen afhænger af reference-klippet. Ren, tydelig tale uden baggrundsstøj giver de bedste resultater.
Opsummering
Plapre viser at man kan bygge brugbar dansk TTS med relativt simple komponenter:
- En kompakt sprogmodel (135M-360M parametre)
- En neural audio-codec (Kanade) til at tokenisere lyd
- Et lineært lag til talerkonditionering
- Store danske taledatasæt (NST-DA, FTSpeech)
Modellerne er open source og kan køres lokalt, på en GPU eller kvantiseret via GGUF på CPU. Al kode og vægte er tilgængelige på GitHub og Hugging Face. Læs mere om Plapre som produkt, eller udforsk vores andre danske AI-produkter.